TurboQuant Explained: How Google Research Achieves 6x Memory Reduction & 8x Faster AI Without Accuracy Loss

Large Language Models (LLMs) have rapidly evolved—but scaling them comes with a hidden cost: memory bottlenecks. While most discussions focus on model parameters, the real constraint in long-context AI systems lies in something less visible but far more critical: the Key-Value (KV) cache.
Enter TurboQuant, a breakthrough compression algorithm introduced by Google Research that fundamentally redefines how LLMs handle memory. It achieves
- 6× reduction in KV cache memory
- Up to 8× faster inference
- Zero accuracy loss
This isn’t just an optimization—it’s a paradigm shift in how AI systems scale.
The Hidden Bottleneck: KV Cache
What is the KV Cache?
In transformer-based models, the KV cache stores intermediate representations (keys and values) for every processed token. This allows models to reuse past computations instead of recalculating them.

However, there’s a catch:
- Memory grows linearly with sequence length
- Long-context tasks (100K–1M tokens) become extremely expensive
- A large model can require hundreds of GBs of memory for KV cache alone
In practice, KV cache—not model weights—is often the biggest bottleneck.
What is TurboQuant?
TurboQuant is a data-oblivious vector quantization algorithm designed specifically to compress KV cache efficiently.
Unlike traditional compression methods, it:
- Works without retraining or fine-tuning
- Maintains mathematical guarantees on accuracy
- Operates in real-time (online quantization)
At its core, TurboQuant compresses high-dimensional vectors into extremely low-bit representations (as low as 3 bits) while preserving their inner product structure, which is critical for attention mechanisms.
How TurboQuant Works (Deep Dive)
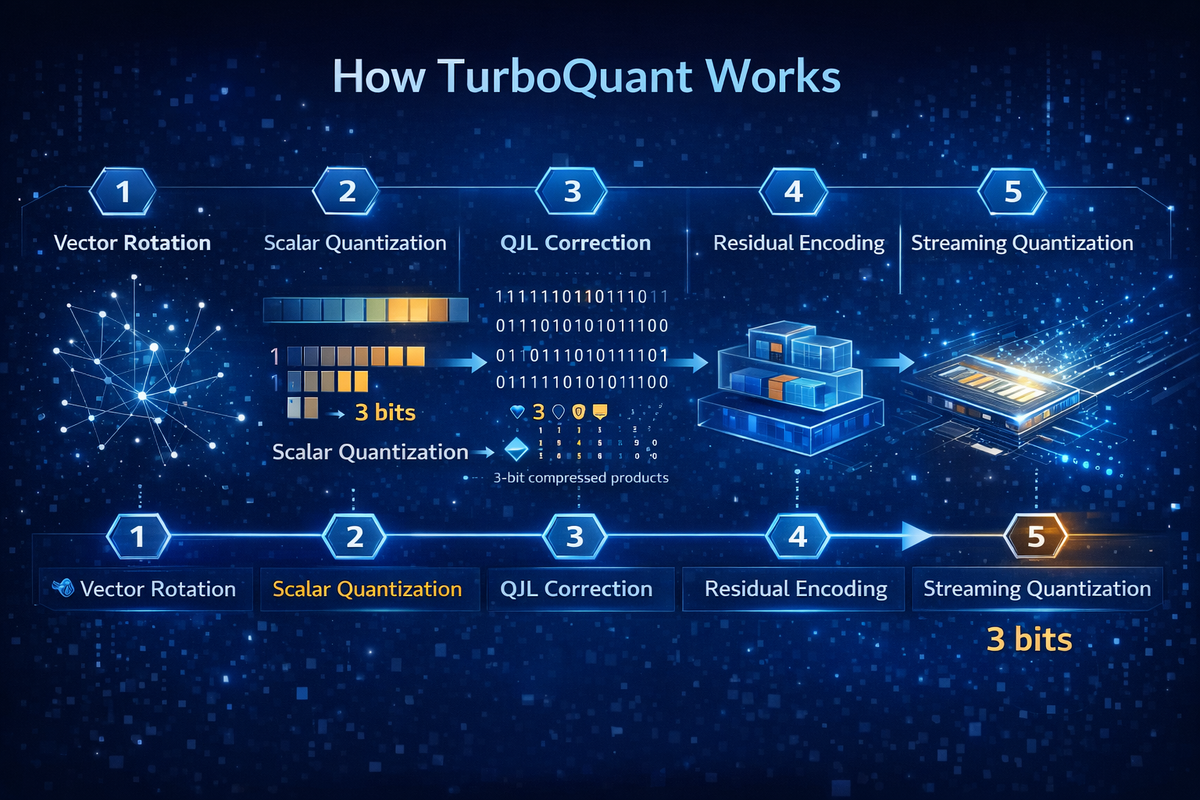
1. Vector Rotation for Uniformity
TurboQuant first applies a random rotation to input vectors.
Why?
- High-dimensional vectors often have uneven distributions
- Rotation makes coordinates more statistically independent
- This enables more efficient quantization per dimension
2. Near-Optimal Scalar Quantization
After rotation, each dimension is quantized independently using optimal scalar quantizers.
This step:
- Minimizes Mean Squared Error (MSE)
- Achieves near information-theoretic optimal compression
3. Fixing Inner Product Distortion
Here’s the real innovation.
Standard quantization introduces bias in dot products, which breaks attention accuracy.
TurboQuant solves this using a two-stage approach:
- Stage 1: MSE-based quantization
- Stage 2: Apply a 1-bit Quantized Johnson–Lindenstrauss (QJL) transform on residuals
Result:
- Unbiased inner product estimation
- Preserved attention scores
- No degradation in model outputs
4. Online (Streaming) Quantization
TurboQuant is designed for real-time inference:
- No need to store full precision KV cache
- Compression happens on-the-fly
- Works seamlessly during both:
- Prefill phase
- Decoding phase
The Breakthrough Results
TurboQuant delivers unprecedented efficiency gains:
Memory Reduction
- KV cache compressed to ~3 bits per value
- 6× smaller memory footprint
Speed Improvements
- Up to 8× faster attention computation
- Reduced memory bandwidth pressure (HBM ↔ SRAM bottleneck)
Zero Accuracy Loss
- Matches full-precision models across benchmarks:
- LongBench
- Needle-in-a-Haystack retrieval tasks
- ZeroSCROLLS
No Training Required
- Works out-of-the-box with models like:
- Gemma
- Mistral
Why TurboQuant is Different from Previous Methods
| Method | Approach | Trade-off |
| Quantization (standard) | Reduce precision | Accuracy loss |
| Pruning | Remove tokens | Information loss |
| Sparsity | Skip computation | Complexity overhead |
| TurboQuant | Optimal vector quantization | No accuracy loss |
Traditional methods struggle because they don’t preserve attention fidelity. TurboQuant directly optimizes for it.
Why This Matters (Big Picture)
1. Longer Context Windows Become Practical
- 1M+ token contexts become feasible
- Enables:
- Full codebase reasoning
- Long video understanding
- Multi-document analysis
2. Smaller Hardware Can Run Bigger Models
- Consumer GPUs can handle larger workloads
- Edge AI becomes more realistic
3. Massive Cost Reduction
- Less memory → fewer GPUs → lower cost
- Higher throughput per machine
4. Unlocks Real-Time AI at Scale
- Faster inference = better UX
- Critical for:
- AI agents
- copilots
- real-time assistants
Industry Impact
TurboQuant addresses a fundamental scaling law of AI:
“As context length grows, memory—not compute—becomes the bottleneck.”
By solving KV cache inefficiency, it enables:
- More scalable LLM deployments
- Efficient multi-agent systems
- Real-time reasoning over massive datasets
This could reshape:
- AI infrastructure design
- GPU memory architectures
- Future transformer optimizations
Limitations & Open Questions
Despite its promise, a few areas need exploration:
- Hardware-specific optimizations (GPU/TPU kernels)
- Integration into frameworks like vLLM or TensorRT
- Performance at extreme compression (<3 bits)
- Interaction with other techniques (e.g., sparsity, MoE)
The Future of LLM Efficiency
TurboQuant is part of a broader shift toward:
- Memory-first AI optimization
- Hybrid compression pipelines
- Hardware-aware model design
We’re entering a phase where:
Efficiency improvements matter as much as model size
Conclusion
TurboQuant is not just another optimization—it’s a foundational breakthrough.
By compressing KV cache with near-optimal mathematical guarantees, Google Research has shown that:
- You don’t need more hardware to scale AI
- You need smarter algorithms
With 6× memory savings and 8× speed gains, TurboQuant could become a core building block for the next generation of AI systems.
Written by
