The Future of AI Research: Inside PaperOrchestra’s Multi-Agent System

Despite all the advancements in AI, research writing remains one of the most time-consuming and complex tasks.
Researchers spend:
- Weeks doing literature reviews
- Days structuring papers
- Hours formatting LaTeX documents
- Countless revisions before submission
Even with tools like ChatGPT or Google Docs, the process is still manual, fragmented, and cognitively heavy.
The problem isn’t just writing — it’s orchestrating the entire research workflow.
That’s exactly where PaperOrchestra comes in.
What is PaperOrchestra?
PaperOrchestra is a multi-agent AI framework designed to transform unstructured pre-writing materials—such as rough idea summaries, experimental logs, and data plots—into full, submission-ready LaTeX manuscripts.
Unlike previous AI writing tools that act as simple "autocompletes," PaperOrchestra acts as a digital research department. It handles everything from literature synthesis and figure generation to API-verified citations and iterative peer-reviewing
How it Works: The Multi-Agent System
The "Orchestra" in its name is literal. Rather than using one giant AI to write the whole paper (which often leads to "hallucinations" or repetitive text), Google uses five specialized agents that work in a coordinated pipeline.
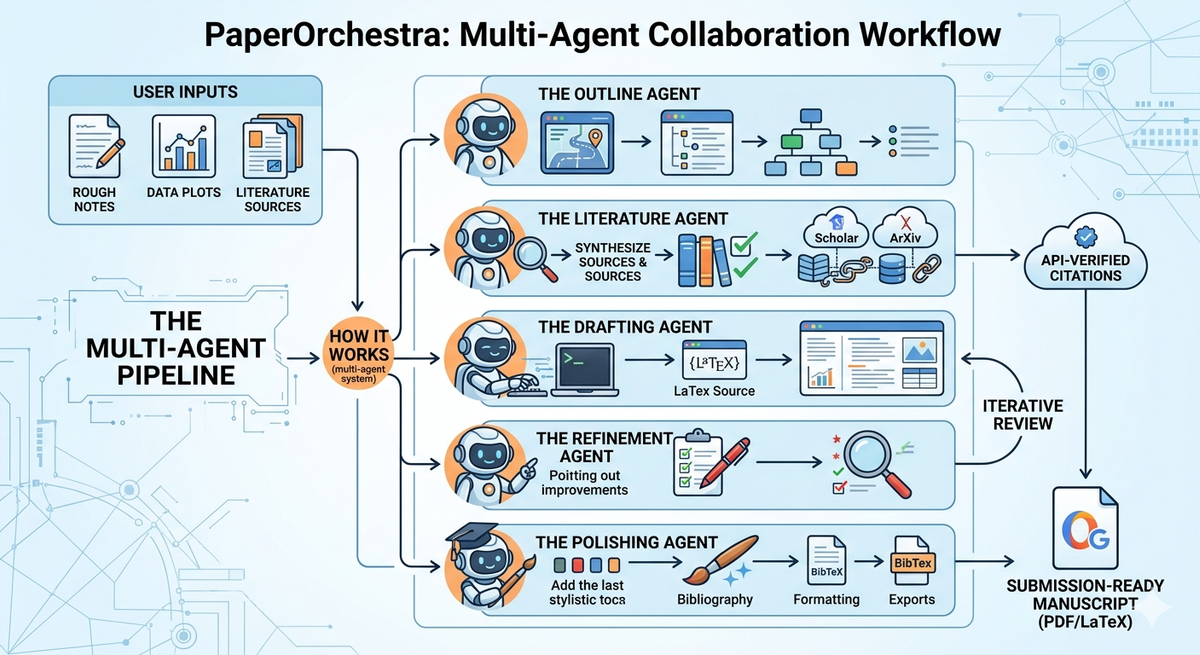
1. The Outline Agent
- This agent acts as the project manager. It ingests your raw notes and experimental data to create a logical structure for the paper, ensuring the narrative flow makes sense before a single sentence is written.
2. The Literature Agent
- Perhaps the most impressive component, this agent searches academic databases to find relevant context. It doesn't just list papers; it synthesizes them. It has a "hard constraint" to ensure that at least 90% of the gathered literature is actively and correctly cited in the text.
3. The Drafting Agent
- This agent takes the outline and the literature review to produce the first full draft in LaTeX. It integrates your experimental results, creates tables, and places figures where they belong.
4. The Refinement Agent (The "Internal Peer Reviewer")
- Before you see the paper, PaperOrchestra "reviews" its own work. This agent identifies gaps in logic, awkward phrasing, or missing citations, and sends instructions back to the Drafting Agent for a second pass.
5. The Polishing Agent
- The final touch. This agent ensures the BibTeX file is perfect, the formatting meets specific conference standards (like CVPR or ICLR), and the tone is academic and precise.
How the Pipeline Works
Here’s how PaperOrchestra transforms an idea into a research paper:
1. Input Stage
- User provides:
- Topic
- Research question
- Optional references
2. Research & Retrieval
- Literature agent scans:
- Academic databases
- Preprints
- Citations
Builds a context-rich knowledge base
3. Planning & Structuring
- Generates:
- Abstract
- Sections (Intro, Methodology, Results, etc.)
- Ensures logical flow
4. Writing Phase
- Produces:
- Detailed explanations
- Technical arguments
- Citations
5. Visualization
- Adds:
- Graphs
- Diagrams
- Tables
6. Formatting & Output
- Converts into:
- LaTeX-ready document
- Structured like a publishable research paper
The Core Problem It’s Solving
- Scale and speed: The literature is too vast for manual coverage; PaperOrchestra accelerates synthesis and iteration.
- Rigor under pressure: Deadlines often compress validation; agents enforce quality gates for methods, stats, and reproducibility.
- Coordination overhead: Multidisciplinary teams lose time on handoffs; orchestration aligns roles, memory, and artifacts.
- Access and equity: Smaller labs and startups gain “virtual staff” to compete with well-resourced institutions.
Key Features
- Role-specialized agents: Each agent optimized for its sub-task with tailored prompting, tools, and memory.
- Tool-use and retrieval: Tight integration with literature search, code execution, plotting, and ref managers.
- Grounding and provenance: Every claim links back to sources, experiments, or calculations.
- Iterative review loops: Built-in peer review and ethics checks before advancing stages.
- Venue-aware writing: Adjustable to target venues’ style, length, citation format, and reviewer expectations.
- Reproducibility-first: Automatic artifact logging, seeds, configuration manifests, and environment specs.
- Human-in-the-loop controls: Researchers approve scopes, pivot decisions, risky methods, and final claims.
Why It Matters: A Big Shift
- From search to synthesis: Moves beyond keyword search to structured understanding and positioning.
- From drafting to designing: Elevates researchers from document production to hypothesis and oversight.
- From siloed tasks to orchestration: Coordinates literature, methods, code, and writing as a single system.
- From episodic to continuous: Enables always-on literature monitoring and rapid update cycles.
Impact potential: Faster cycles from idea to validated result; broader participation in high-quality research; improved transparency via enforced provenance and reproducibility.
Real-World Impact: Where It Can Help Now
- Academic labs: Accelerate related work, baselining, and ablations to focus human effort on novel ideas.
- Industry R&D: Speed literature landscaping, competitive analysis, and internal white papers for product decisions.
- Policy and standards: Rapid synthesis of evidence for technical standards or safety frameworks.
- Healthcare and science: Streamline systematic reviews, protocol drafting, and result write-ups (with strict oversight).
- Startups: Level the playing field by automating heavy-lift research tasks without large teams.
Limitations and Concerns
- Factuality and hallucinations: Without rigorous grounding, generated claims may overstate or drift; strict source binding and reviewer gates are essential.
- Methodological shortcuts: Agents may favor convenient experiments over externally valid designs; human oversight must enforce relevance.
- Ethical and authorship norms: Credit assignment, disclosure of AI assistance, and responsibility for errors require clear policy.
- Data rights and privacy: Literature access, dataset licenses, and sensitive data must be respected; compliance auditing is required.
- Venue acceptance: Some conferences/journals require explicit disclosure; expectations on AI-generated text are evolving.
- Compute and cost: Running multi-agent pipelines with experimentation can be resource-intensive; budgeting and caching are needed.
Practical Example Workflow (Illustrative)
- Seed objective: “Evaluate retrieval-augmented generation for legal QA on long documents.”
- Surveyor: Retrieves 60 recent papers; clusters methods (RAG variants, memory, compression); highlights evaluation gaps on long-context statutes.
- Problem Framer: Defines hypotheses on chunking vs. compression trade-offs; selects statutory QA datasets.
- Methodologist: Designs baselines (BM25+LLM, vanilla RAG) and proposed memory-augmented RAG; sets metrics (Exact Match, F1, citation accuracy) and power analysis.
- Experiment Runner: Executes runs with fixed seeds; logs wandb/MLflow artifacts; exports plots.
- Analyst: Computes confidence intervals; runs significance tests; performs error taxonomy.
- Writer/Editor: Generates venue-formatted draft with figures, tables, and linked artifacts; Reviewer flags overclaims and requests an additional ablation; cycle repeats once.
Final Thoughts
PaperOrchestra signals a new era of AI-powered research.
It’s not just about writing faster —
it’s about rethinking how knowledge is created.
The real question is no longer:
“Can AI help with research?”
It’s now:
“How far can AI go in automating discovery itself?”
Written by
